


Close your eyes and listen to the sound around you. No matter whether you are in a crowded office, cozy home, or open space of nature, you can distinguish the environment with sound around you. One of the five major senses of humans is hearing, so audio plays a significant role in our life. Therefore, being able to organize and exploit values in audio data with deep learning is a crucial process for AI to understand our world. An important task in sound processing is enabling computers to distinguish one sound from another. This capability enables computers to do things ranging from detecting metal wearing in power plants to monitoring and optimizing fuel efficiency of cars. In this post, we will use bird sound identification as an example. We will detect locations of bird calls in recordings produced in natural settings and classify species. By converting audio data to image data and applying computer vision models, we acquired a silver medal (top 2%) in Kaggle Cornell Birdcall Identification challenge.
When a doctor diagnoses heart problems, he can either directly listen to the patient’s heartbeat or look at the ECG, a diagram that describes the heartbeat, of the patient. The former usually takes longer - it takes time for the doctor to listen - and harder - memorizing what you heard can be hard. In contrast, visual perceptions of ECG allows a doctor to absorb spatial information instantly and accelerates the tasks.
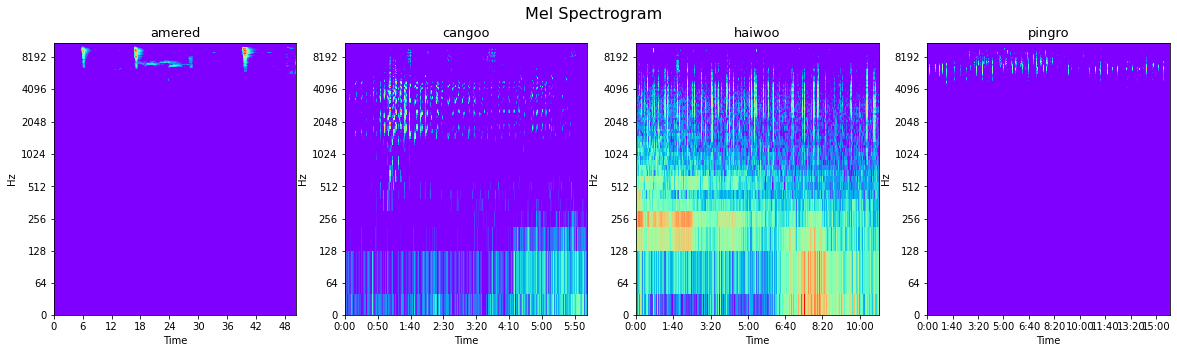
The same rationales apply to our sound detection tasks. Here are four audio clips and corresponding spectrograms of four bird species. Even human eyes can see the differences between species instantly based on color and shapes.
import IPython.display as ipd
ipd.Audio('img-tony/amered.wav')
ipd.Audio('img-tony/cangoo.wav')
ipd.Audio('img-tony/haiwoo.wav')
ipd.Audio('img-tony/pingro.wav')