



In Part I we introduced a set of techniques to identify an ordinal encoding for any categorical variable that we called a Rainbow method. We suggest to use this method instead of One-hot. In Part II we put the method into practice and applied it to a MassMutual data science model. We have seen better results for Rainbow vs One-hot. Here in Part III, we will justify mathematically the advantages of the Rainbow method over One-hot.
We will start with a simple example, and then proceed with a full generalization and a simulation. In the final part, we will discuss various assumptions and limitations of the Rainbow method and provide actionable recommendations to get the most out of Rainbow. Please note that the discussion below applies to any tree-based algorithm such as random forest and gradient boosting. For example, any model implemented via XGBoost.
How exactly does Rainbow help?
Consider the following example:
- assume a binary classification problem, with output variable having values 0 and 1;
- assume we have only one categorical variable V and no other variables;
- assume V has exactly four categories with values v1 < v2 < v3 < v4;
In the case of a nominal variable, the values simply represent numeric codes assigned to each category. - assume each value of V has close to the same number of samples in the data;
- assume an ideal separation will give {v1 & v2} samples f-score = 1 and {v3 & v4} samples f-score = 2, where f-score represents some decision function used for separation (e.g. Gini impurity, information gain, etc.).
I.e. the data generating process would separate between the groups {v1 & v2} and {v3 & v4}, but would not distinguish values within each group.
Let's consider two cases - Rainbow and One-hot. For Rainbow, we will use V directly to build a decision tree. For One-hot, we will need to create four binary variables - let's call them V1, V2, V3, V4, where Vi = 1 if V=vi and 0 otherwise.
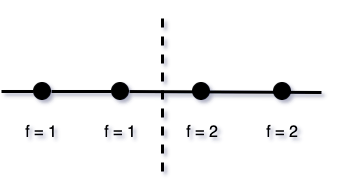
Let's for simplicity build a single decision tree. Assume a simple algorithm that picks each next feature randomly, and compares all values of that feature to make the best split. In the case of the Rainbow, samples from two categories will be sent to the left branch and samples from two other categories will be sent to the right branch of the tree. In such a situation a natural split occurs between v2 and v3, and Rainbow would need one split,
Figure 1
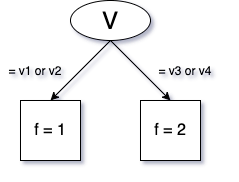
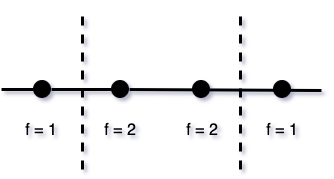
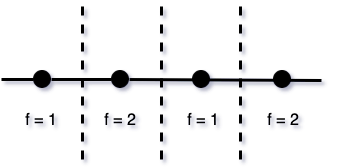
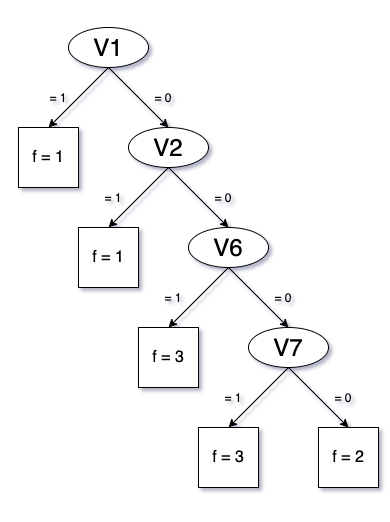
while One-hot would need two or three splits. Here are two examples:
Figure 2
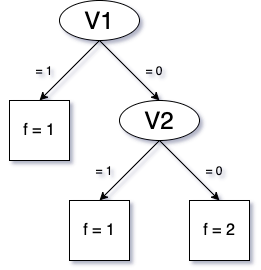
Figure 3
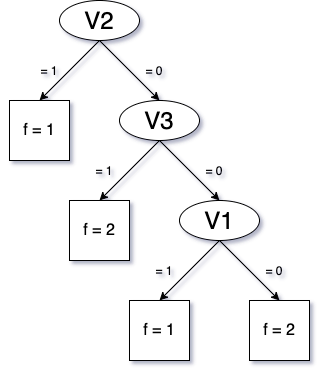
In other words, assuming a clear order between categories, the Rainbow method is strictly better at separating samples because it makes fewer splits. In this example, it finds the single perfect split between v2 and v3. The One-hot method goes through four scales instead of one and does not naturally incorporate a combination of information from a few features.
Figure 4
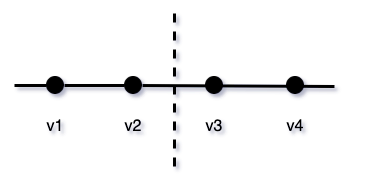
But what happens if the categories do not follow a perfect order?
Generalizing simple example
Let's look at a more general case, where the values of the categorical variable are in a different order. Below are some examples of 4 categories and their f-scores. The same f-score justifies combining values into a group. For instance, 1,1,2,2 represents our example above, where the first two categories get assigned f = 1, and the last two categories get assigned f = 2, and the split should happen in the middle.
The number of splits would depend on the order in which these categories appear.
For Rainbow orders:
- 1,1,2,2 and 2,2,1,1 the number of splits would be 1;
Figure 5
- 1,2,2,1 and 2,1,1,2 the required number of splits would be 2;
Figure 6
- 1,2,1,2 and 2,1,2,1, the required number of splits would be 3.
Figure 7
For One-hot, the orders below would represent the order in which the One-hot features are selected and added to the tree:
- 1,1,2,2 and 2,2,1,1 the required number of splits would be 2;
As in our simple example above (Figure 2), the first split would be made on V1, the second on V2, and that would be sufficient to separate between the samples with f = 1 and f = 2.
- 1,2,2,1 and 2,1,1,2 and 1,2,1,2 and 2,1,2,1 the number of splits would be 3.
In these examples, as shown above (Figure 3), three splits would be needed given the order in which binary features enter the tree.
Note that the Rainbow and One-hot orders described here are not the same orders, so we cannot compare them directly. For the Rainbow method, we look at the order at the top (in which categories appear on a single scale), while for One-hot we look at the order at the bottom (in which categories are picked by the model). Nevertheless, we see that on average Rainbow is better as it provides a lower number of splits - best case 1, average case 2, worst case 3; while One-hot gives best case 2, average case $\frac 83$, and worst case 3. In fact, this is true in general as we will demonstrate below.
General Case: Random Rainbow vs One-hot
Assume that a certain categorical variable $V$ has $K$ categories with values v1 < v2 < v3 ... < vk. Then:
- One-hot would create $K$ features $V1, V2, ..., VK$, where $Vi$ = 1 if $V$ = vi and 0 otherwise;
- Rainbow would create a single feature, where all the categories appear on one scale. We can keep the name of this variable $V$.
Assume $K$ categories optimally would need to be split into $g$ groups of size $G_1,G_2,...,G_g$. By size $G_i$ we mean a number of categories out of $K$ (not the number of samples). Obviously, $\sum_i G_i = K$.
For instance, in the simple example above - the order is 1,1,2,2:
Figure 8
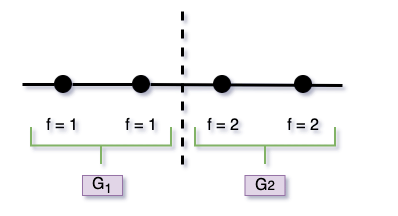
and $K=4$, $g=2$, $G_1=2$ consisted of {v1, v2}, and $G_2=2$ consisted of {v3, v4}.
Another example where the order is 1,2,2,1:
Figure 9
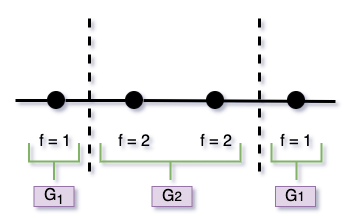
Here $K=4$, $g=2$, $G_1=2$ consists of {v1, v4}, and $G_2=2$ consists of {v2, v3}.
Unlike the simple example of the perfect Rainbow, in this general case the $K$ categories would appear in random order, and our Rainbow would be random. However, for the purposes of computation, we only care about groups of the same f-values rather than about actual categories. In other words, if v1 and v2 samples produce the same f-score, it does not matter whether the order is (v1, v2) or (v2, v1).
For One-hot, the order that would matter is the one in which One-hot splits are made. This order is also assumed to be random. This is the order that we would always refer to when talking about One-hot.
In reality, the One-hot splits are not fully random and the order of them being picked by the model varies depending on the number of samples in each category, subsamples of columns chosen, and other hyperparameters. That can be both in favor or against the case for One-Hot. We will come back to this assumption later in the article (see Randomness Assumption), and for now, will proceed with assuming randomness for simplicity.
While the orders that matter for Rainbow and One-hot are not the same, it helps to couple them to make comparisons. Let's compute the required number of splits in best, average, and worst cases.
Main Comparison Metric
As in the simple example above, in this general case of random Rainbow vs One-hot, we will compare the number of splits made by the model to approximate the data generating process. Why is it our main metric? Fewer splits means:
- less time;
- less computational resources;
- simpler model;
- less overfit;
- more effective model.
What is best, average, and worst case?
Below we compare Rainbow and One-hot feature transformations at their most efficient, least efficient, and average states.
The best Rainbow uses the perfect order of categories that agrees with the data generating process. The average Rainbow is a random order of categories. The worst Rainbow is the order that needs the maximum number of splits to represent data genrating process.
The best One-hot model would pick up the highest gain binary features to build every tree node. The average One-hot model would pick up binary features randomly to build the tree. The worst One-hot model would pick up the binary features in a way to make the maximum number of splits in the tree.
Therefore, in the best case, One-hot would require $K - G_{max}$ splits, where $G_{max} = max_i G_i$ is the maximum of $G_i$. This best-case $K - G_{max}$ is obtained when each group except the largest one gets one split per category and the remaining largest group has the same answer and therefore wouldn't require any additional splits. To prove that one cannot do better, observe that if a few categories do not appear on any tree node, i.e. no splits are made, then they are "combined", and there is no way to distinguish the values in these two categories.
Rainbow
In the best case of a Rainbow - the values are in perfect order, and the minimum splits are needed. Given $g$ groups, that would require $g-1$ splits. This happens when groups are together and it simply splits at $g-1$ points to separate $g$ groups.
For example, two splits are needed for the perfect Rainbow with three groups 1,1,2,2,2,3,3.
One cannot do better since if there is no split between two groups there is no way to distinguish them.
Comparison
$$K - G_{max}=(\sum_{i=1}^g G_i)-G_{max}=(\sum_{i\ne max}G_i) \geq (\sum_{i\ne max} 1) = g-1$$ Hence, the best Rainbow is better than the best One-hot.
Average Case
One-hot
From the logic presented in the best case, it follows that
The number of splits that One-hot needs would be $N$ - the number of categories that are chosen before the remaining ones are in one group.
Figure 10 shows the best case - where all the remaining ones belong to the largest group. In the average case, the remaining group can be any group or any group's part. We expect that, when building an average tree, a homogenous group would be broken into pieces. What we care about is that the tree building should end when reaching some homogenous group.
In the best case, $N = K - G_{max}$. In the average case, $N = K - R$ where $R$ is the size of the remaining group.
For example, if the order in which One-hot categories are chosen for the tree is 1,1,2,2,3,3,2,2,2 then $R=3$ since the last group 2,2,2 is of size 3. The number of categories $K=9$, thus the number of splits would be $K-R=6$.
It is easiest to compute the expected value of $N$ by using the less common formula $\mathbb E[X] = \sum_{j} \mathbb P[X \geq j]$ applied to $R$. We then utilize the formula for hypergeometric distribution to calculate each probability and achieve the result below.
Rainbow
From the best case logic, it also follows that
The number of splits that random Rainbow needs would always be $D$ - the number of consecutive pairs in Rainbow order that are in distinct groups.
In the best case, $D=g-1$.
For example, in the case of Rainbow order 1,1,2,2,3,3,2,2,2 the splits will happen in 3 places, and these are the only places where the group is changed and the values in consecutive pairs belong to distinct groups.
Let's calculate the expected value of $D$. We do this by calculating for $K-1$ consecutive pairs as potential places for splitting the probability that the f-score is different. It is easier to subtract from one the probabilities that f values in each consecutive pair are the same. We sum through all possible groups $i$ to compute the likelihood that two consecutive values belong to one group.
\begin{align} \mathbb E[D] &= (K - 1) \cdot (1-\frac{ \sum_i G_i \cdot (G_i-1)} {K(K-1)}) \notag \\ &= (K-1)-\frac{ \sum G_i \cdot (G_i-1)} {K} \notag \end{align}Comparison
An easy way to see that $\mathbb E[D]$ is larger than $\mathbb E[N]$ is the stochastic coupling since both $N$ and $D$ can be obtained by starting from $K-1$ and subtracting $1$ for each consecutive pair in the same group; except in the case of $N$, all these pairs have to be in the string at the end. Due to this restriction $N$ is always larger.
Worst Case
One-hot
In the worst case for One-hot, the number of splits is $K-1$ when one goes through all but one category to get to one group remaining.
Rainbow
In this case, the number of needed splits is
$\min( (K - 1), 2 \cdot (K-G_{max}))$
as we can only get up to two splits per each category that is not in the largest group.
Indeed, if there are no consecutive pairs of values that belong to the same group then the number of splits would be $K-1$, for example here 3,2,1,3,1,2.
At the same time, if there is a prevalent group and some minority groups, for example, 1,1,1,2,1,1,3,1,1, the number of splits will equal the number of minority groups - $K-G_{max}=2$ in this case (2 and 3) times 2 which is the maximum number of splits that each minority group introduces - one to the left and one to the right.
As a result, the required number of splits will be the minimum between the two cases above.
Comparison
Clearly, the number of splits for Rainbow is less than or equal to that of One-hot for the worst case as well.
Simulation
We have shown above that theoretically in a general case Rainbow method outperforms One-hot in best, average, and worst-case scenarios. Let's look at the empirical simulation: we applied the formulas for best, average, and worst-case number of splits for Rainbow and One-hot to compare the distribution of splits for some examples of the data generating processes.
Figure 11

One can clearly see that the simulation confirms our theoretical finding:
- Best Rainbow always needs an equal or fewer number of splits than Best One-hot: the green line is almost always below the light green dotted line;
- Average Rainbow always outperforms Average One-hot: the orange line is always strictly below the light orange dotted line;
- Worst Rainbow needs an equal or fewer number of splits than worst One-hot: the purple line is either below or coincides with the light purple dotted line.
Conclusion
As we have shown above, Rainbow method outperforms One-hot in their respective best, average, and worst states. However, not any Rainbow is better than any One-hot. Rather, the Rainbow distribution of number of splits is stochastically dominant to that of One-hot, if the randomness assumption is satisfied.
Discussion of Assumptions
While the results above appear to be very optimistic, we should discuss the method limitations and assumptions we made.
Single Tree Assumption:
The use of a single decision tree vs forest.
This assumption does not really impact the outcomes, since a single tree is equivalent to a forest of trees with depth 1. In fact, if our method works on simpler models - this only increases the advantages.
Randomness Assumption:
One-hot picks columns randomly.
We assumed above that our machine learning algorithms pick features somewhat randomly, and then make a split by using full scales of values of those features. One might argue that in reality, before making any split, algorithms such as XGBoost would look at many splits across all features and will pick the best.
We understand that this is a strong assumption and in reality, the One-hot splits are not fully random. However, they are also not fully deterministic. First, most of the algorithms don't run all possible comparisons within all features to make a choice about the node, rather some quick set of rough comparisons, which is done to avoid overfitting. Second, various hyperparameters have a substantial effect on which split will be chosen: subsample of columns, subsample of rows, maximum depth, etc. Third, if we are talking about bigger categorical variables with many categories, One-hot creates a lot of features, and a randomness assumption would be not far from the truth. Finally, counts of samples for each category can be highly uneven, and that also gets us closer to randomness and is likely to yield worse results for One-hot than for Rainbow.
Under the randomness assumption, the distribution of the number of splits is strictly better for Rainbow than for One-hot. However, one might argue that in reality we could wind up choosing between a good One-hot (assuming intelligent algorithms and relaxing randomness assumption) and a random Rainbow.
In fact, the quality of a Rainbow is an unknown. We can see that the Average Rainbow (orange line) is between Best One-hot (light green dotted line) and Average One-hot (light orange dotted line). So it is important to try and find a good order Rainbow, that approaches the data generating process.
The proposed solution here is very simple and clear - pick a few, choose the best. We invite you to try a few possible Rainbow ordinal encodings and compare them side by side to each other and One-hot. Your data and problem context will be the best tools at your disposal to choose the best order for encoding. We also recommend that you look at a few metrics, as well as model runtime. We expect that the Rainbow method would provide you with much better overall results, especially if you have many categorical variables with many values.
Final Notes
This set of articles just opens the conversation about the Rainbow method, and by no means represents and exhaustive discussion. In future investigations, we could compare it with other dimensionality reduction methods (such as PCA), consider missing values and how they fit the Rainbow framework, analyze limitations and implications of combining seemingly unrelated features into a single Rainbow. We hope to open the discussion for further questions and feedback on this method.